
It comes from this blog post by David Taylor.
It's a really cool graph, but then, I tend to find analysis of baby names a bit frustrating because they almost always rely strictly on the written, or orthographic, forms of the names. It's not that the way people spell their children's names doesn't matter, but it's half of the puzzle. For example, I'm named after my grandfather. He was German (more specifically, a Donauschwob), so he spelled his name <Josef>, and pronounced the initial sound like <y>, which in the IPA is /j/. When naming me, my parents had a whole bunch of options. Would the pronounce my name like my grandfather did, or like most English speakers would? And how would they spell it? They wound up settling on the English pronunciation, and the German spelling. I've made a little diagram displaying a very partial set of options my parents had in choosing my name.
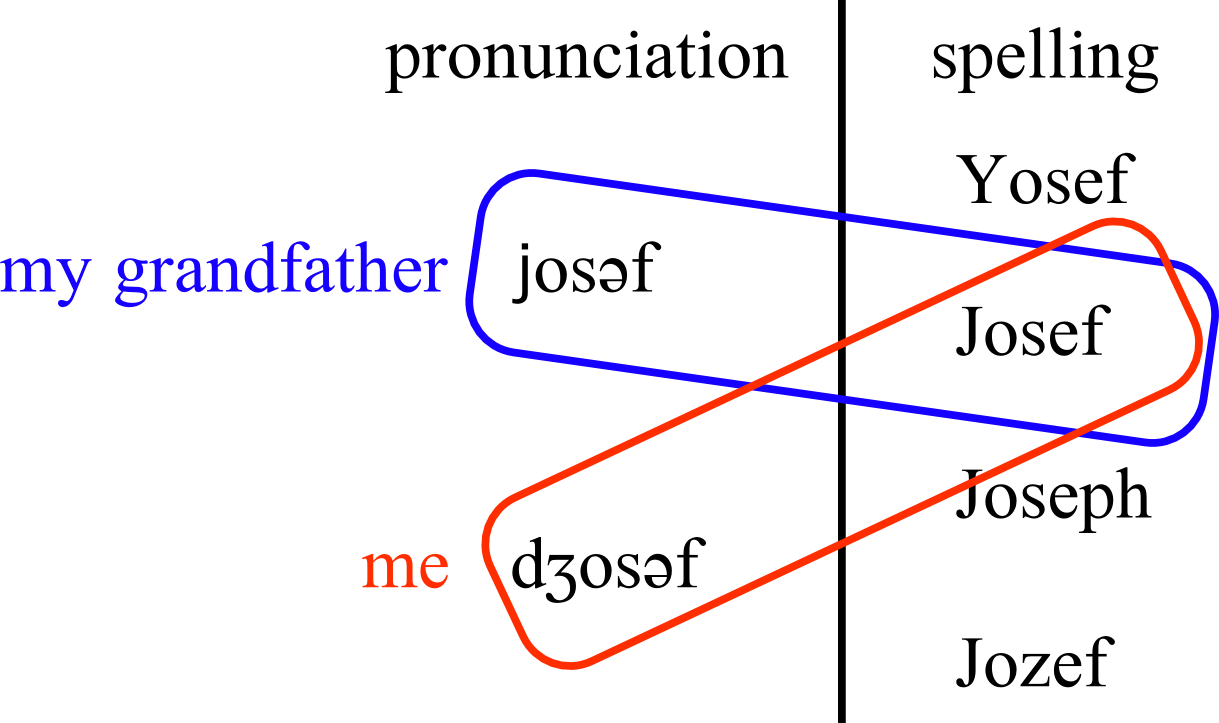
And of course, Sarah Jessica Parker played a woman named /sændi/ who spelled it <SanDeE☆> in Steve Martin's LA Story, so clearly the spelling of proper names is an important expressive dimension, but still just half the picture.
So, I decided to look at a bit more at popular linguistic structures in baby names. Hadley Wickham has already compiled the top 1000 baby names in the US per year since 1880 (https://github.com/hadley/data-baby-names), and Kyle Gorman has a nice python module that syllabifies CMU dictionary entries (https://github.com/kylebgorman/syllabify). So I put together some sloppy code to analyze it (https://github.com/JoFrhwld/names). The biggest weakness to my approach is the number of names which are not to be found in the CMU dictionary. 2525 out of the total 6782 names in the data (about 40%) aren't in CMU, so this post should be understood as being for entertainment purposes only.
One other thing that bugged me about the name final <n> plot is that it seemed kind of arbitrary to focus on the final letter of the name. I suspect that it's a real trend that people noticed eyeballing lists of names, but that it wasn't compared against other kinds of trends. I went ahead and labeled name initial and name final syllables, codas, onsets and rhymes as being special, but I'm not going to single them out.
Kicking things off, there's a graph of popular syllables between 1880 and 2008. To be included in the graph, a syllable had to be in the top 3 most popular in any given year. The y-axis is how many times more frequent the syllable is than if syllable selection were random. It's not frequency rated, that is, this is just the distribution over names that have that syllable, not babies.


But maybe the reason boy's name final /n/ isn't shining through like you might expect is because of phonological reasons. A boy's name ending in a word final syllabic /n/ is necessarily going to pull the preceding consonant into the syllable with it. Looking at the plot above, it's not likely that the preceding consonant is totally random either, cause we've only got /t, s, d/ (all coronals) and vowels preceding the /n/. But for the hell of it, here's the same kind of plot as the ones above, but this time with syllable rhymes.

I'd like to play around with this data a bit more if I get some time. It occurred to me that you could come up with a few different ways of generating popular names from different eras by randomly sampling popular syllables, or by estimating transition probabilities between syllables and going on a random walk that way.
All my code and the data are up on github, if anyone else wants to play around with it: https://github.com/JoFrhwld/names.
I'm curious about the ER0# names too here (and I have to admit, I'm not too familiar with your way of coding things here). Is this just for "Christopher" and "Alexander"? This, of course, makes me wonder to what extent the effects reflect the sudden gain/loss in popularity of a single very popular name.
ReplyDeleteYeah, ER0# would correspond to those names and names like "Carter" etc (I can't take the blame for the coding scheme, that's just the CMU dictionary flavor of arpabet). At any rate these trends can't be due to the gain or loss of a very popular name, because they're not frequency rated. A billion babies could've been named "Alexander" one year, but "Alexander" would still just count as 1 of the 1000 most popular names that year. These are trends over names, not babies, so there would have had to have been a bunch of different ER0 names for it to show up as popular.
DeleteGreat stuff! I've been looking at this recently as well, for the Linguistics of Names class I teach. It's neat to explore the tradeoffs between spelling and sound in naming. As their first homework assignment, I have my students compare the change over time in names that end in to the change in names that end in . -final names have been on an upward trajectory in both the US and the UK, but -final names have not. So it seems like it's not just ending in [n] that makes a name popular.
ReplyDeleteThere has also been a crazy rise in recent years in names that rhyme with 'Aidan', of all spellings and initial consonants. In 2010 there were 40 of these names among the top 1000 in the US, from Aaden to Zayden, compared to 1984 when Braden was the only one. And that's not even taking into account their phonological cousins Jaelyn, Layton, Mason, etc. Most of these are novel enough not to be in CMUdict, so I think the number of n-final names may be underestimated fairly substantially without some hand-transcribing, which I still haven't brought myself to do yet.
I don't know why I expected my angle brackets to come through. That should have been < n > -final names on the upward trajectory vs. < ne > -final names which are not.
Delete